9-1-3 Raspberry Piの準備作業
ここではRaspberry Piに必要な準備作業について記載します
USBマイクロホンの認識確認
(1) Raspberry piに、USBマイクロホンとスピーカーを接続します

(2) USBデバイス検索コマンドの入力
pi@raspberry:~ $ lsusb


音声処理ライブラリsoxのインストール
音声データの操作には、soxライブラリを使用します
(1) soxライブラリをインストールします
pi@raspberry:~ $ sudo apt-get install alsa-utils sox libsox-fmt-all
音声入力、音声再生の確認・設定
(1) 音声入力のカード番号の確認
pi@raspberry:~ $ arecord -l

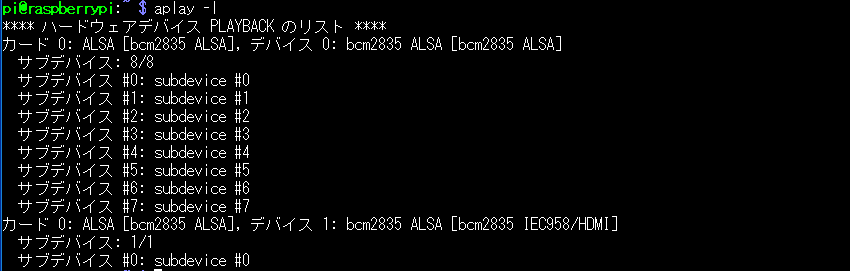
(2) 再生のカード番号の確認
pi@raspberry:~ $ aplay -l
(3) 音声入力音量の設定
pi@raspberry:~ $ amixer -c1 sset Mic,0 16

(4) 再生音量の設定
pi@raspberry:~ $ amixer -c0 sset PCM,0 400

(5) 音声出力先の設定
pi@raspberry:~ $ amixer cset numid=3 1
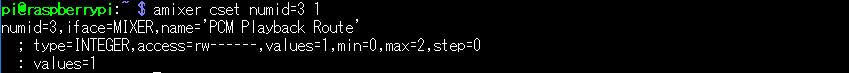
※ 再生音声を3.5mmミニジャックから出力させる為の設定です
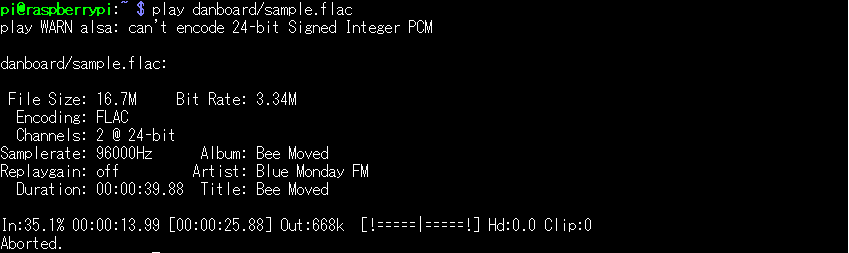
(6) 再生音声の確認
flacファイルを使用して再生できるか確認します
「音楽 ダウンロード 無料 flac」などで検索すると無料で入手もできます
pi@raspberry:~ $ play danboard/sample.flac
Google APIキーの取得
Googleが提供している音声認識のクラウドサービスを使用します
音声をテキストに変換(SpeechToText)してくれる部分です
(1) Googleアカウントを作成する
https://accounts.google.com/SignUp?hl=ja
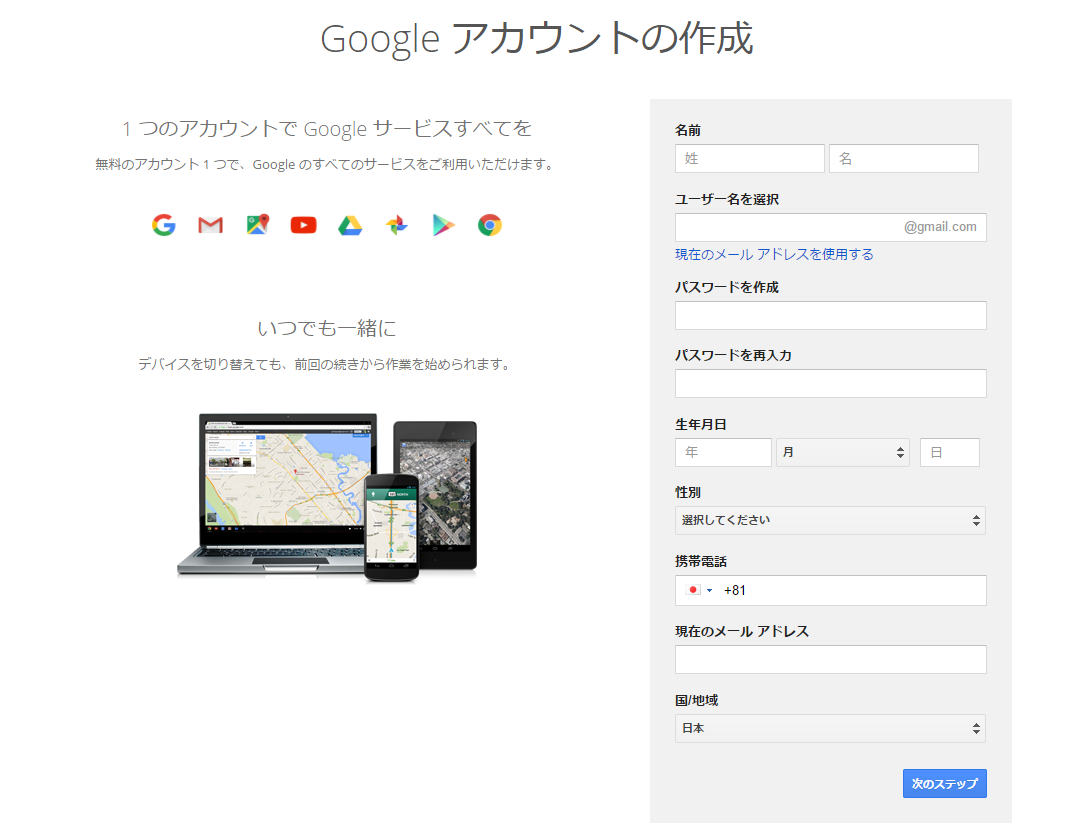
(2) Chrome-devグループへの加入
「google chrome dev group」で検索します
投稿するにはグループに参加してくださいをクリックして、Chrome-devグループに加入する
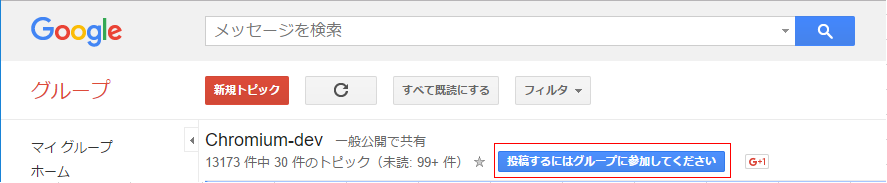
(3) Google Developer Consoleサイトへのログイン
自分のGoogle IDでログインします
タイトルバーにある、プロジェクトの選択をクリックします
(4) 右側にある+ボタンをクリックします
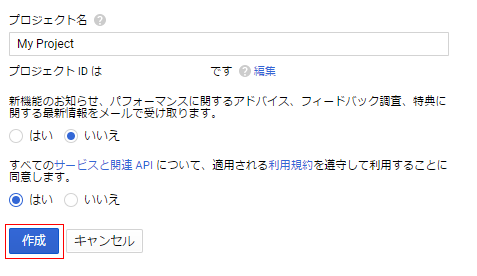
(5) デフォルトのプロジェクト名は、”My Project”になっているので、好きな名前に変更してもOKです
入力ができたら、作成ボタンをクリックします
画面が「API Manager」の「ライブラリ」へ移動します
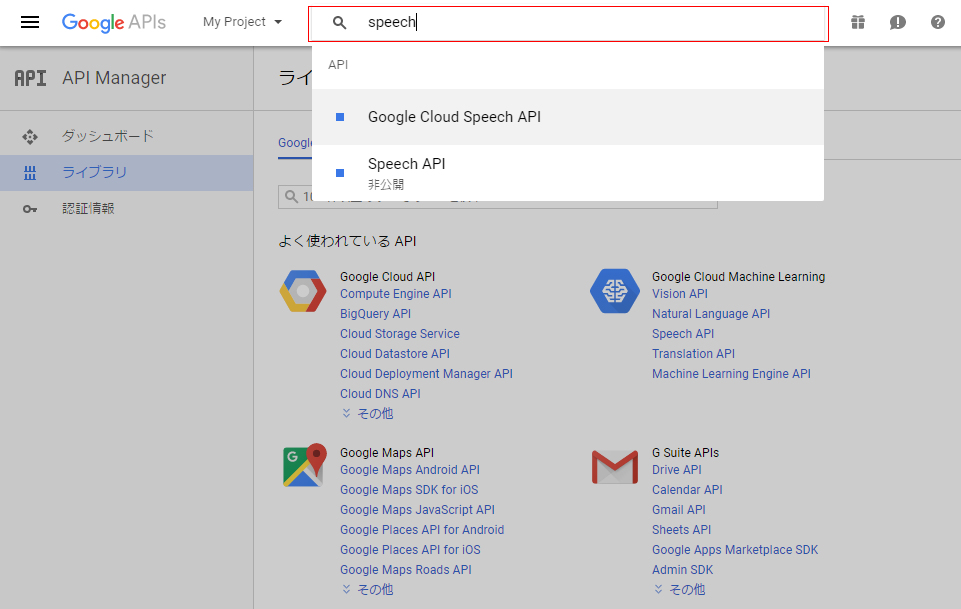
(6) 検索フォームに「speech」と入力すると、「Speech API」が現れるので選択します
※ Google-devグループに加入していないと、表示されないので注意が必要です
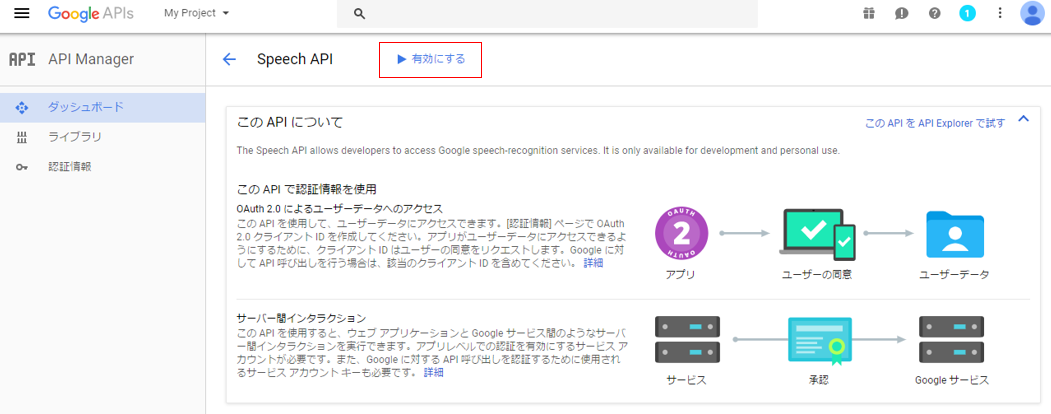
(7) 「有効にする」をクリックして、Google Speech APIを有効化する
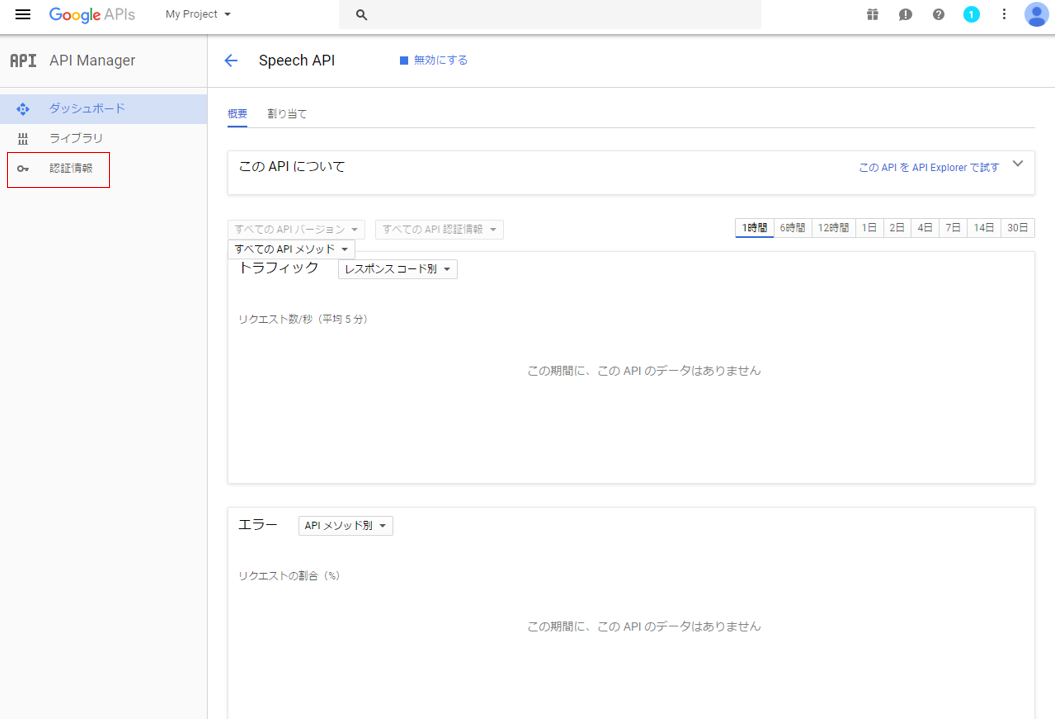
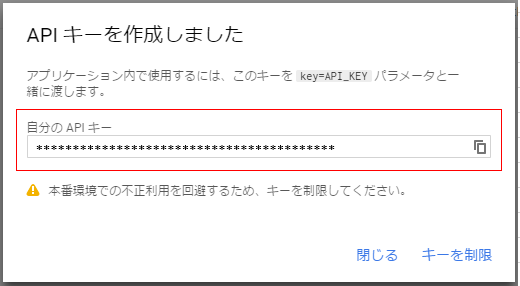
(8) 有効化ができたら、次に認証情報をクリックします
(9) 認証情報を作成で、APIキーを選択します
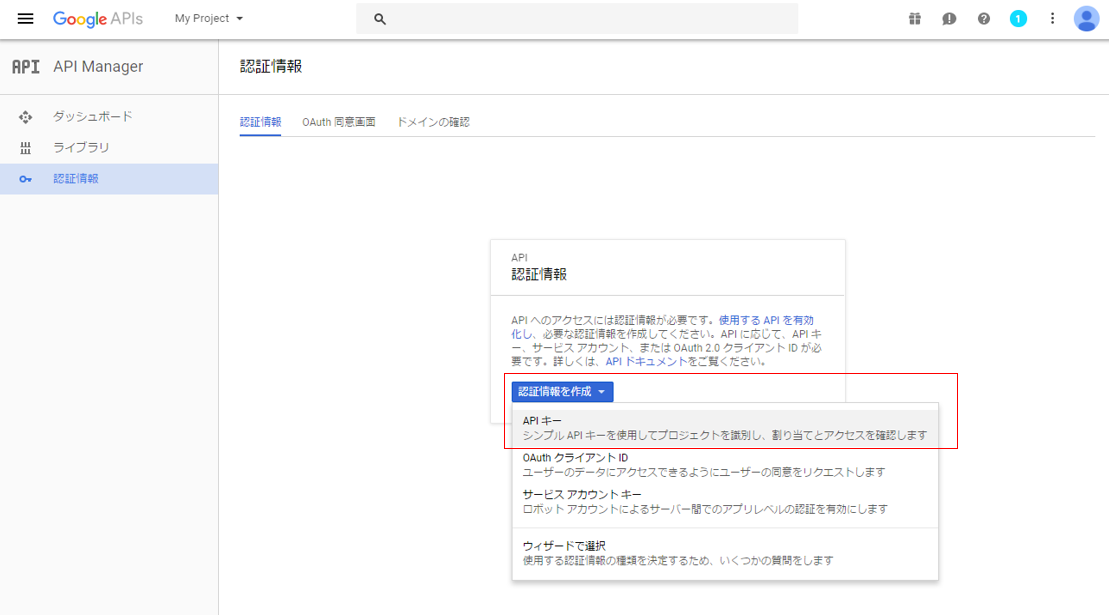
(10) APIキーを作成しましたと表示が出るので、このAPIキーは大切に保管しておいてください
※ 音声認識の実行で、APIキーが必要になってきます
Docomo APIキーの取得
docomoが提供している雑談会話のクラウドサービスを使用します
リクエストがあったテキストの内容に対して、適切な返信をしてくれる部分です
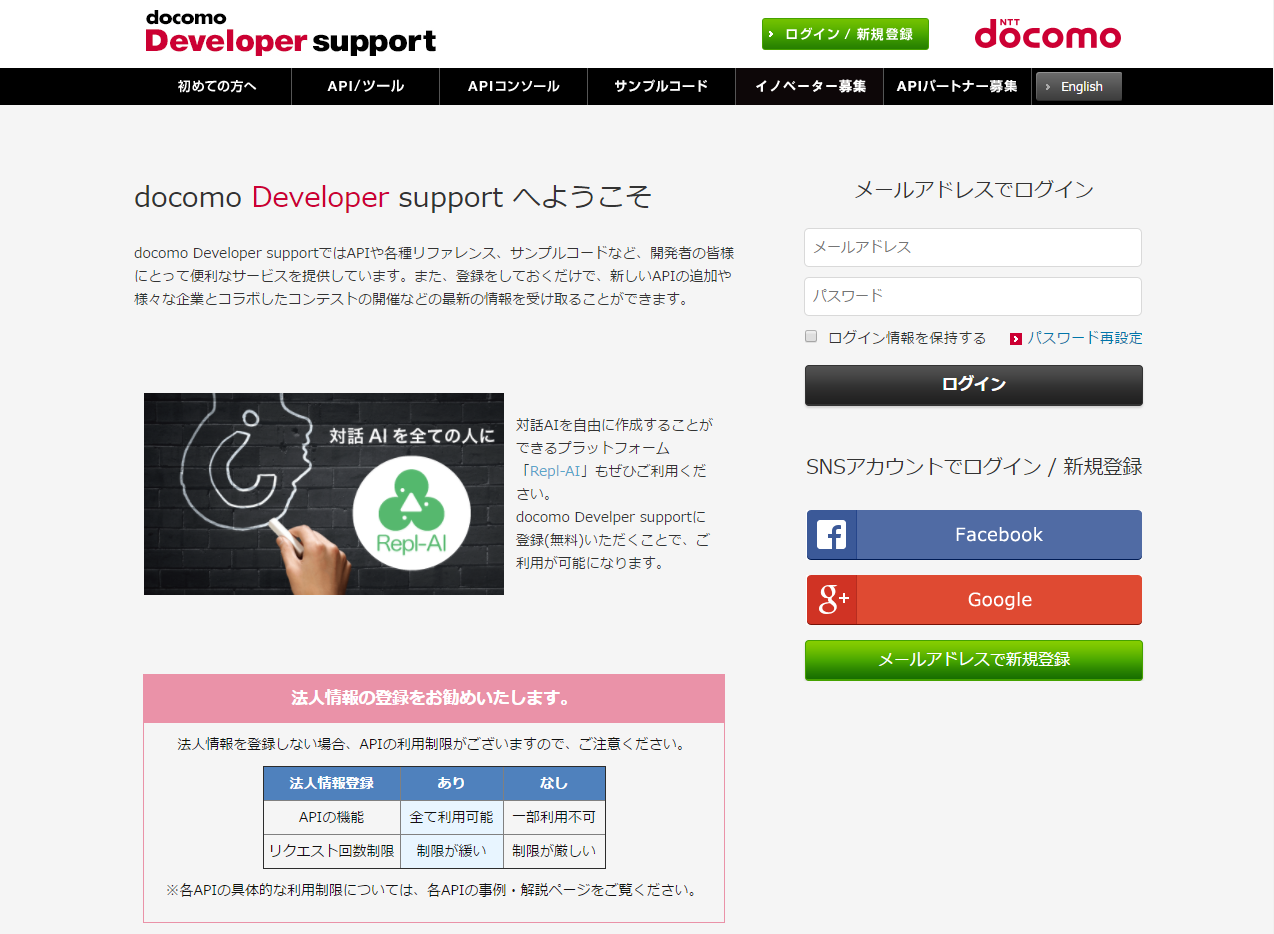
(1) docomo Developer supportサイトにアクセスする
ログイン/新規登録をクリックする
(2) メールアドレスで新規登録、またはSNSアカウントでログイン/新規登録を選択してください
※ 登録手続きの内容については省略します
(3) 登録が完了したら、マイページのAPI利用申請・管理をクリックします
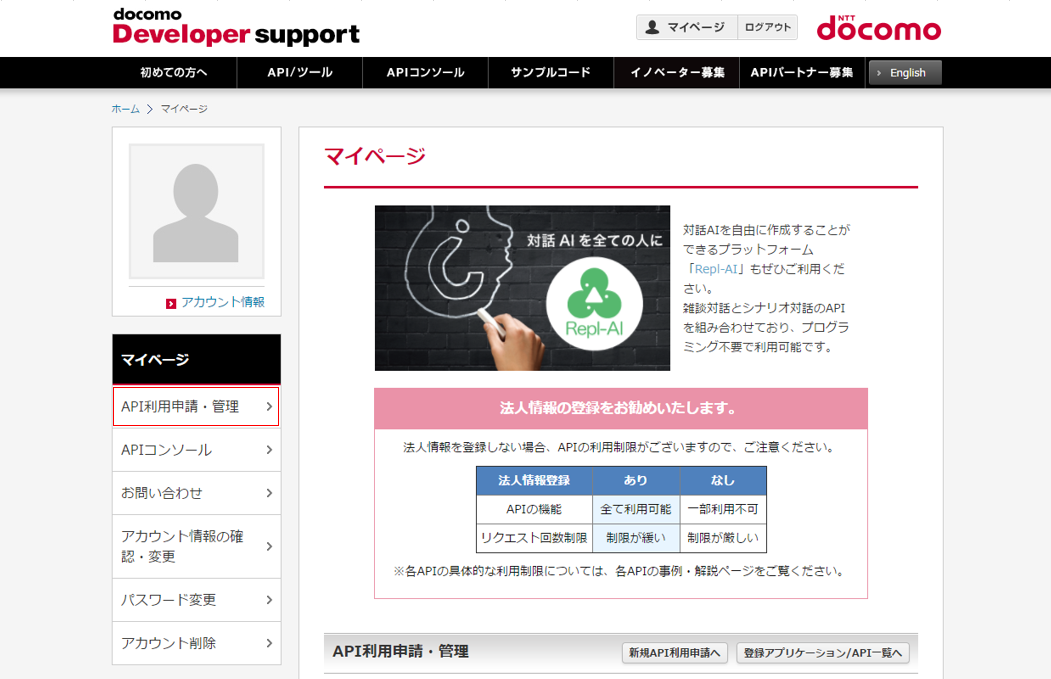
(4) 新規API利用申請へをクリックします
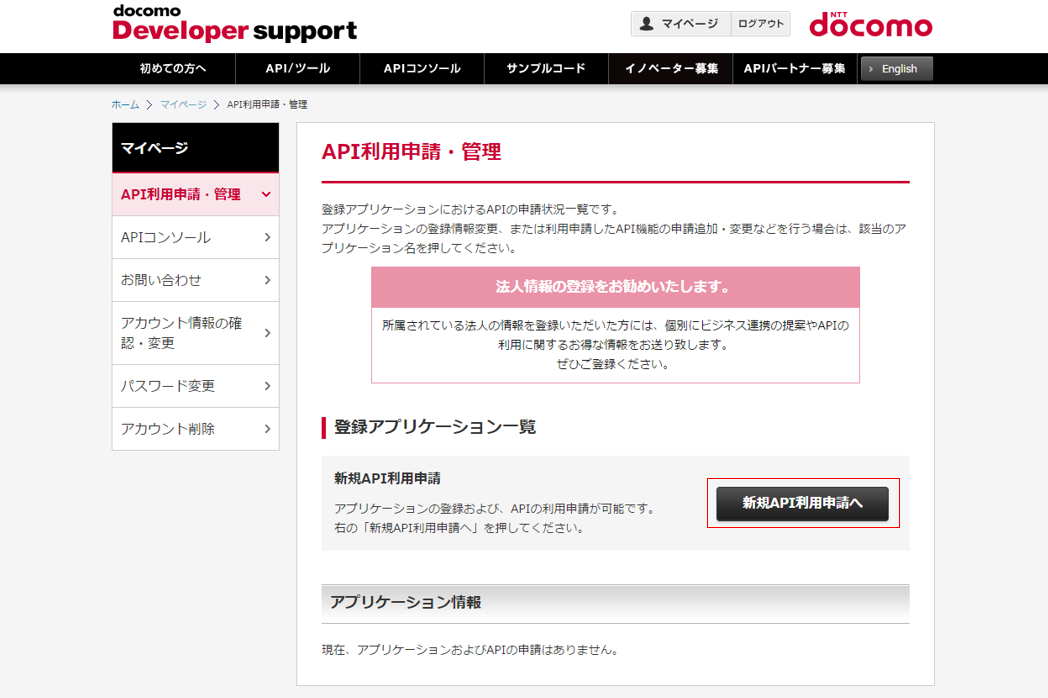
(5) アプリケーションの登録します。入力項目に従って、入力して下さい
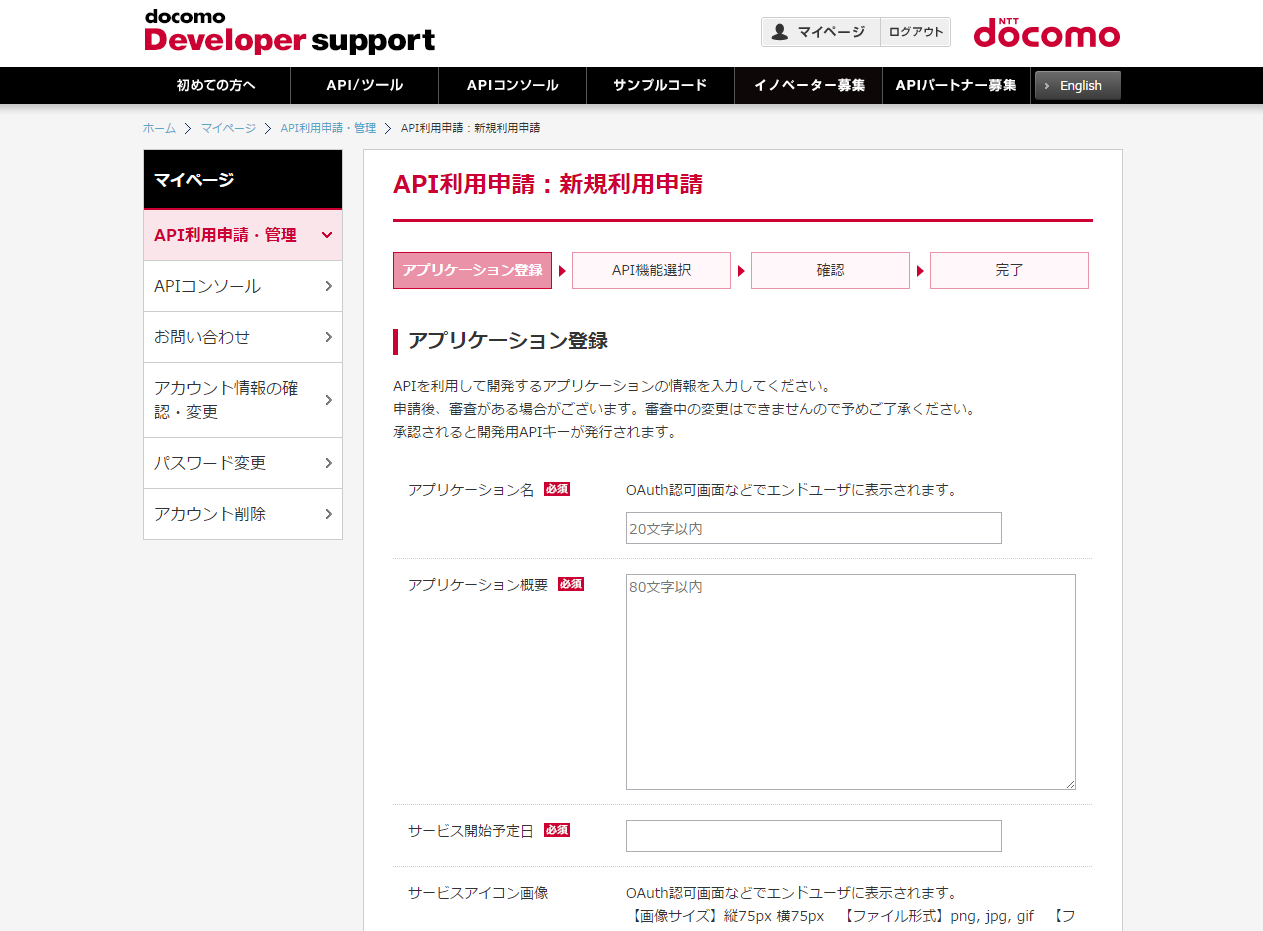
(6) API機能選択で雑談会話にチェックしてください
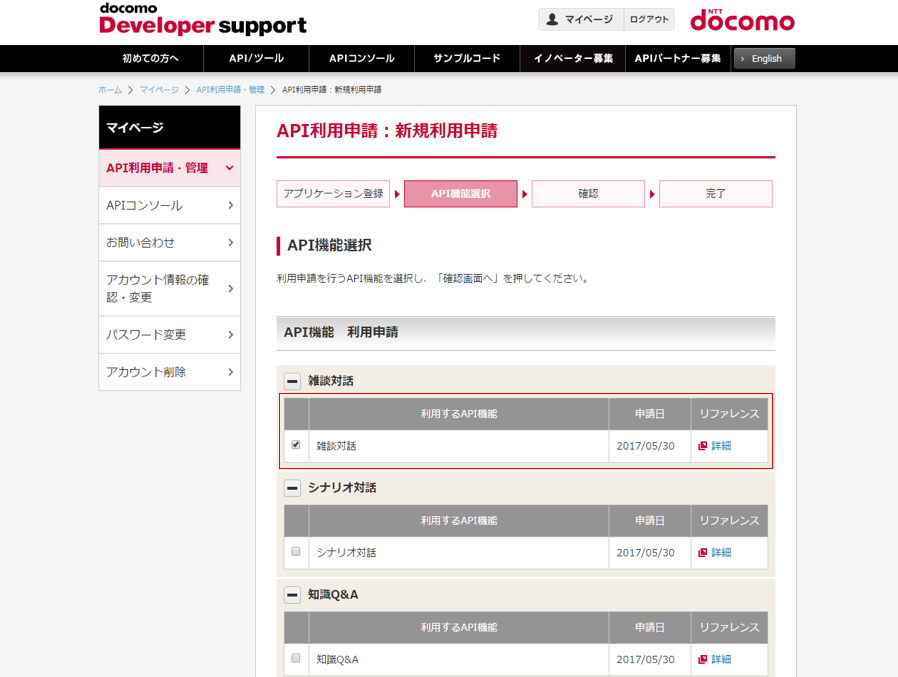
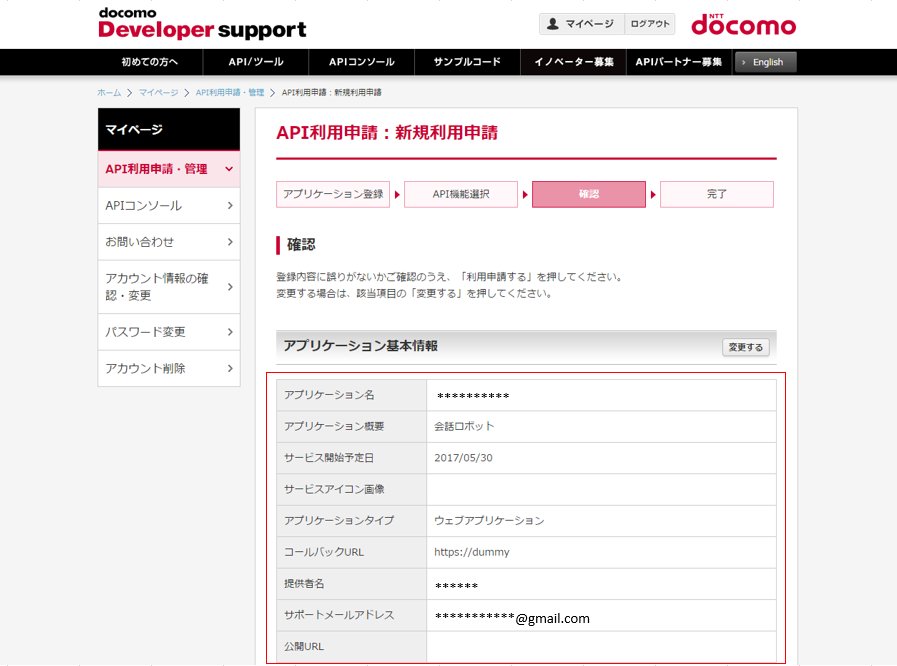
(7) アプリケーションの登録で入力した情報に間違いがないかを確認します
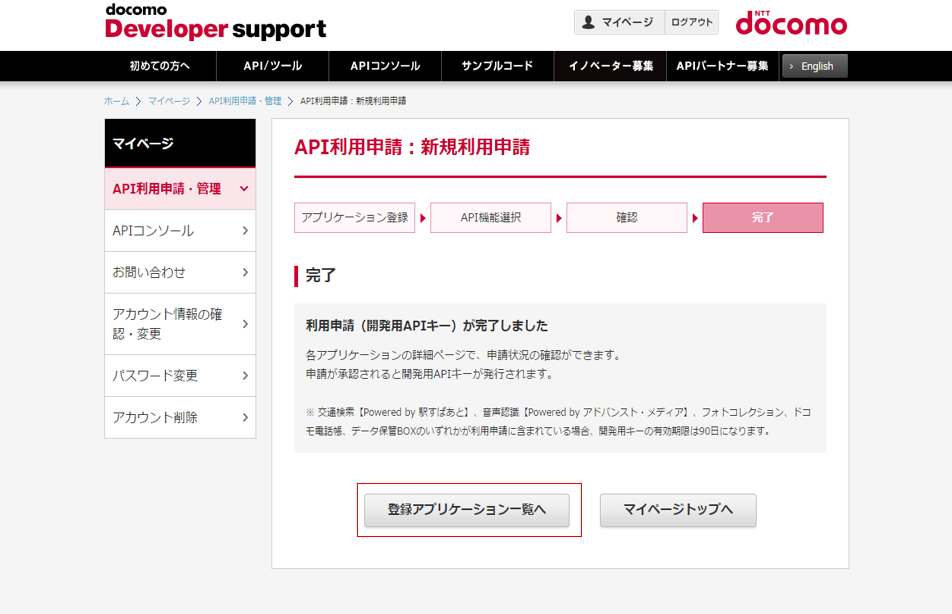
(8) 完了画面が表示されたら、登録アプリケーション一覧へをクリックします
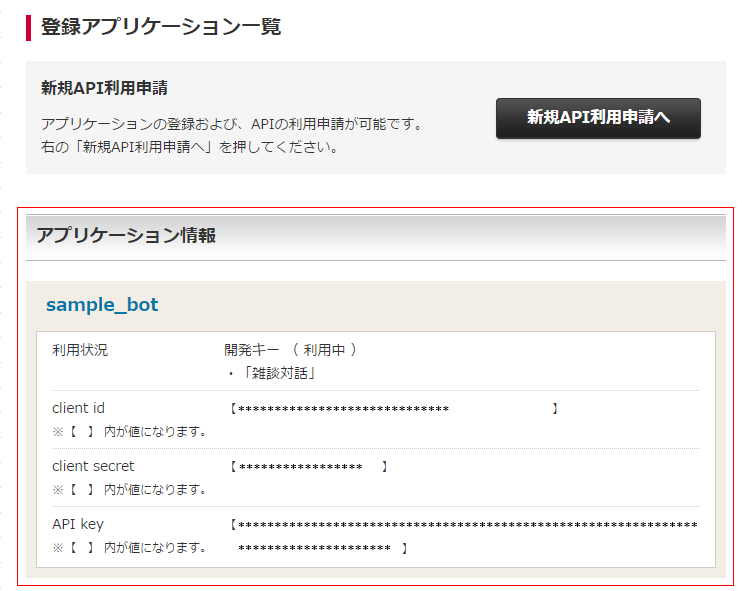
(9) 登録アプリケーション一覧では、アプリケーション情報が表示されます
※ 雑談会話では、このAPIキーが必要になってきます
音声合成ソフトウェアのインストール
音声合成については、Open JTalkを使用します
(1) Open JTalkのインストール
pi@raspberry:~ $ sudo apt-get install open-jtalk
(2) 辞書ファイルのインストール
pi@raspberry:~ $ sudo apt-get install open-jtalk-mecab-naist-jdic
人工会話ロボットのプログラムを作成
danboard.py
#!/usr/bin/env python
# coding=utf-8
import http.client
import requests
import json
import os
import time
import sys
import subprocess
import serial
import random
# '===シリアル通信設定=========='
sr = serial.Serial('/dev/ttyACM0', 9600)
# '===APIキーの設定=========='
# GoogleAPIキー
GOOGLE_APIKEY = '********************'
# DOCOMOAPIキー
DOCOMO_APIKEY = '******************************'
# '===URLの設定=========='
# Google_speechのURL
GOOGLE_SPEECH_URL = 'https://www.google.com/speech-api/v2/recognize?xjerr=1&client=chromium&'\
'lang=ja-JP&maxresults=10&pfilter=0&xjerr=1&key='
# DOCOMOのURL
DOCOMO_URL = 'https://api.apigw.smt.docomo.ne.jp/dialogue/v1/dialogue?'\
'APIKEY={}'.format(DOCOMO_APIKEY)
# '===音声発話時間設定=========='
FIRST_LISTEN_SECONDS = 1
LISTEN_SECONDS = 5
# '===オーディオ設定=========='
AUDIO_HDS = {'Content-type': 'audio/x-flac; rate=11025'}
# '===音声入力のファイルパス=========='
VOICE_IN_PATH = '/home/pi/danboard/message.flac'
# '===音声出力のファイルパス=========='
VOICE_OUT_PATH = '/home/pi/danboard/voice.wav'
# '===変数設定=========='
action_status = 0
# '===定数設定=========='
CODE_PROMPT = 1
CODE_GOOGLE = 2
CODE_BEFORE = 1
CODE_AFTER = 2
CODE_STATUS = 0
CODE_START_STATUS = 1
CODE_AFTER_STATUS = 2
# '===メッセージの格納変数=========='
google_msg = 'GoogleAPIで変換したテキスト'
cmd_msg = 'コマンドプロンプトからの入力あり'
# '===エラーメッセージの格納変数=========='
usb_err_msg = 'USBマイクロホンを確認してください'
inet_err_msg = 'イーターネット接続を確認してください'
voice_err_msg = '音声認識サービスを確認してください'
docomo_err_msg = '雑談会話サービスを確認してください'
# '===発話メッセージの格納変数設定=========='
speak_msg1 = '何か私とお話しましょう'
speak_msg2 = 'こんにちは。ダンボードです。'
speak_msg3 = 'あなたとお話がしたいです'
speak_msg4 = '少しおしゃべりしませんか'
speak_msg5 = 'とても退屈です'
# '===コマンドプロンプトからの入力(テスト用)=========='
argv = sys.argv
argc = len(argv)
if argc == 2:
SYSTEM_MSG = sys.argv[1]
else:
SYSTEM_MSG = ''
# '===音声入力(録音)=========='
def listen(seconds, listen_num, status_code):
if listen_num == 1:
print('録音テスト...')
# 音声入力の録音
else:
print('録音開始...')
if status_code == 2:
# 目を緑色(シリアル通信)
sr.write(b'G')
cmdline = 'AUDIODEV=hw:1 rec -c 1 -r 11025 ' + VOICE_IN_PATH + \
' trim 0 ' + str(seconds)
os.system(cmdline)
return os.path.getsize(VOICE_IN_PATH)
# '===GoogleAPI(SpeechToText)での音声認識=========='
def convert_to_text():
print('音声をテキストに変換中...')
f = open(VOICE_IN_PATH, 'rb')
voice = f.read()
f.close()
url = GOOGLE_SPEECH_URL + GOOGLE_APIKEY
hds = AUDIO_HDS
try:
reply = requests.post(url, data=voice, headers=hds).text
except IOError:
return '#CONN_ERR'
except:
return '#ERROR'
print('results:', reply)
objs = reply.split(os.linesep)
for obj in objs:
if not obj:
continue
alternatives = json.loads(obj)['result']
if len(alternatives) == 0:
continue
return alternatives[0]['alternative'][0]['transcript']
return ""
# '===Docomo(会話返信)=========='
def return_speech(message, num):
# コマンドプロンプトから入力ありの場合
if num == 1:
print('コマンド入力メッセージ...' + message)
else:
print('テキスト変換メッセージ...' + message)
url = DOCOMO_URL
payload = {'utt': message}
try:
r = requests.post(url, data=json.dumps(payload))
except:
return '#ERROR'
return r.json()['utt']
# '===音声発話(OpenJTalk)=========='
def speak(message):
print('音声発話メッセージ...' + message)
JDIC_DIR='/var/lib/mecab/dic/open-jtalk/naist-jdic/'
VOICE_DATA='/home/pi/ai/mei/mei_happy.htsvoice'
cmdline = 'echo ' + message + ' | open_jtalk -x ' + JDIC_DIR + \
' -m ' + VOICE_DATA + ' -ow ' + VOICE_OUT_PATH + \
' -s 17000 -p 100 -a 0.03'
subprocess.call(cmdline, shell=True)
os.system('play ' + VOICE_OUT_PATH)
# '===時刻取得関数=========='
def current_milli_time():
return int(round(time.time() * 1000))
# '===待機時間取得=========='
def get_sleep_time(action_status):
if action_status == 1:
sleep_time = 0.01
else:
sleep_time = 4
return sleep_time
# '===ダンボードの発話処理=========='
def danboard_speak_msg(no):
if no == 1:
msg = speak_msg1
elif no == 2:
msg = speak_msg2
elif no == 3:
msg = speak_msg3
elif no == 4:
msg = speak_msg4
elif no == 5:
msg = speak_msg5
else:
msg = ''
speak(msg)
# '===起動メッセージ受付処理=========='
def voice_recept():
while True:
print('起動メッセージ受付...')
# 音声入力
# 時刻を取得
t0 = current_milli_time()
size = listen(LISTEN_SECONDS, CODE_AFTER, CODE_START_STATUS)
print('size:' + str(size))
t = current_milli_time() - t0
# 音声入力処理時間が2秒より短い場合
if (t < 2000):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(usb_err_msg)
speak(usb_err_msg)
time.sleep(10)
continue
print('listened:' + str(t) + 'ms')
print('voice data size=' + str(size))
# 音声認識
# 時刻を取得
t0 = current_milli_time()
# GoogleAPI(SpeechToText)で音声をテキストに変換
message = convert_to_text()
print('message:' + message)
print('recognized:' + str(current_milli_time() - t0) + 'ms')
# インターネットへの接続エラーが発生した場合
if (message == '#CONN_ERR'):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(inet_err_msg)
speak(inet_err_msg)
time.sleep(10)
continue
# 音声認識に対してのエラーが発生した場合
elif (message == '#ERROR'):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(voice_err_msg)
speak(voice_err_msg)
time.sleep(10)
continue
# 開始メッセージ処理
if message != "":
if message in 'スタート':
print("start")
no_word = 0
wifi_err = 0
danboard_start_up(no_word, wifi_err)
# '===ダンボード処理開始=========='
def danboard_start_up(no_word, wifi_err):
try:
while True:
print('danboard_start_up...')
print('音声入力の開始...')
# マイクを相手に向ける(シリアル通信)
sr.write(b'S')
# 音声入力
# 時刻を取得
t0 = current_milli_time()
size = listen(LISTEN_SECONDS, CODE_AFTER, CODE_AFTER_STATUS)
action_status = 1
print('size:' + str(size))
t = current_milli_time() - t0
# 音声入力処理時間が2秒より短い場合
if (t < 2000):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(usb_err_msg)
speak(usb_err_msg)
time.sleep(10)
continue
print('listened:' + str(t) + 'ms')
print('voice data size=' + str(size))
# 音声認識
# 時刻を取得
t0 = current_milli_time()
# GoogleAPI(SpeechToText)で音声をテキストに変換
message = convert_to_text()
print('message:' + message)
print('recognized:' + str(current_milli_time() - t0) + 'ms')
# インターネットへの接続エラーが発生した場合
if (message == '#CONN_ERR'):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(inet_err_msg)
speak(inet_err_msg)
time.sleep(10)
continue
# 音声認識に対してのエラーが発生した場合
elif (message == '#ERROR'):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(voice_err_msg)
speak(voice_err_msg)
time.sleep(10)
continue
# 連続5回何も話されない場合
if (len(message) <= 1):
no_word = no_word + 1
if (no_word >= 5):
# 目の光を赤青緑に点滅(シリアル通信)
sr.write(b'A')
rand_no = random.randint(1, 5)
# ダンボードのメッセージ発話
danboard_speak_msg(rand_no)
no_word = 0
continue
# 終了メッセージの場合
if message != "":
if message in 'ストップ':
print("stop")
# 左腕を初期状態に戻す
sr.write(b'E')
# 処理待ち
time.sleep(3)
# 目の光を青色(シリアル通信)
sr.write(b'B')
voice_recept()
# 会話返信
if message != "":
# 時刻を取得
t0 = current_milli_time()
print(google_msg)
# GoogleAPIで変換したテキストを渡す
message = return_speech(message, CODE_GOOGLE)
print('会話返信メッセージ...' + message)
print('replied:' + str(current_milli_time() - t0) + 'ms')
# DOCOMO会話返信でのエラーが発生した場合
if (message == '#ERROR'):
print(docomo_err_msg)
speak(docomo_err_msg)
time.sleep(10)
continue
# 音声発話
speak(message)
print('talked:' + str(current_milli_time() - t0) + 'ms')
except KeyboardInterrupt:
# 左腕を初期状態に戻す
sr.write(b'E')
# 処理待ち
time.sleep(3)
# 目の光を青色(シリアル通信)
sr.write(b'B')
pass
if __name__ == '__main__':
print('ダンボード起動')
# 目の光を青色(シリアル通信)
sr.write(b'B')
if SYSTEM_MSG == '':
# 処理待ち
time.sleep(2)
print('音声入力のテスト...')
listen(FIRST_LISTEN_SECONDS, CODE_BEFORE, CODE_STATUS)
# 音声受付処理
voice_recept()
else:
# コマンドプロンプトからの入力がある場合
print('===================================')
print(cmd_msg)
print('===================================')
# コマンドプロンプトからの入力文字を渡す
message = return_speech(SYSTEM_MSG, CODE_PROMPT)
print('会話返信メッセージ...' + message)
# DOCOMO会話返信でのエラーが発生した場合
if (message == '#ERROR'):
# 目の光を赤色(シリアル通信)
sr.write(b'R')
print(docomo_err_msg)
speak(docomo_err_msg)
time.sleep(10)
# 処理待ち
time.sleep(2)
# 目の光を赤青緑に点滅(シリアル通信)
sr.write(b'A')
# 音声発話(テスト)
speak(message)
# 目の光を青色(シリアル通信)
sr.write(b'B')
# 処理終了
sys.exit()
ファイルの配置
作成したArduinoとRaspberry Piのプログラムを配置していきます
ファイルの配置には、FTPソフト(Cyberduck)を使用します。
インストールされてない場合こちらを参考にしてください → Cyberduckのインストール
(1) 今回は下記のように、ファイルを配置します